What if the most valuable content strategy input in your toolkit isn’t a keyword research tool, but a monitoring dashboard that shows you exactly which competitor pages AI models are citing, in what format, and in what language? Most companies that have invested in AI Search monitoring are drowning in citation data without a clear system for turning it into content decisions. At Radyant, we use monitoring data as a key input for content strategy, and this guide shows you exactly how we do it.
Key takeaways
- AI Search monitoring replaces keyword research as your primary content planning input. Citation gap data, format analysis, and fan-out query intelligence tell you what to create, in what format, and in what language with far more precision than search volume estimates.
- There are four distinct monitoring-to-action loops that drive content decisions: citation gap analysis (what topics to cover), format opportunity analysis (blog vs. YouTube vs. help center), multi-language citation analysis (translation priorities), and fan-out query analysis (content depth requirements).
- Monitoring tools provide diagnosis, not treatment. Peec AI will show you where competitors are winning. The strategic layer that turns data into content decisions is what this guide teaches.
- First-party results back this approach. Using monitoring-informed content strategy, we’ve helped clients achieve 110%+ citation share from owned content alone, discovered YouTube as a high-converting citation source, and identified “0 volume” topics that generated 60+ leads in under 6 months.
Disclaimer: At Radyant, we use Peec AI as our AI Search monitoring tool and we’re also a Trusted Partner in their directory. That said, there are other tools out there that offer similar functionality. What matters most is the quality of your prompts, not which tool you use to track them.
Why monitoring data is a better content strategy input than keyword research
Here’s a scenario we see constantly: a Head of Marketing opens Semrush, filters for keywords with 500+ monthly volume and KD under 40, and builds a content calendar from the results. The content gets published. Some of it ranks. Traffic goes up. Pipeline doesn’t move.
The problem isn’t the content quality. The problem is the input. Keyword research tools tell you what people type into Google. They don’t tell you what AI models cite when a potential buyer asks ChatGPT “What’s the best [your category] software for mid-market companies?”
AI Search monitoring data answers a fundamentally different question: When a buyer asks an AI model about your category, whose content does the model trust enough to cite?
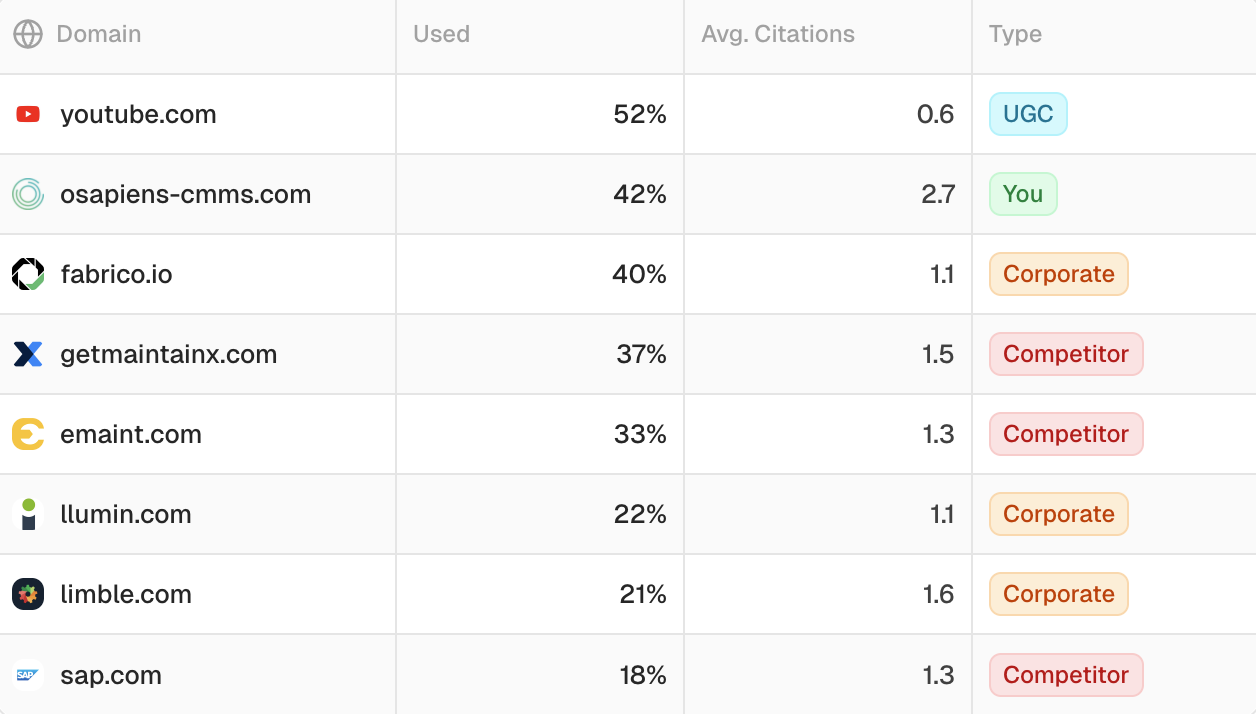
Top domains cited in the Peec AI workspace of our client osapiens
That distinction matters because AI Search is growing fast and skewing commercial. According to a Peec AI analysis of 10M+ ChatGPT prompts, commercial intent queries trigger a background web search 53.5% of the time, compared to just 18.7% for purely informational queries. And nearly 8 in 10 B2B buyers say AI Search has changed how they conduct research, with 29% starting research via platforms like ChatGPT more often than Google.
When we started using monitoring data as the primary content strategy input for clients like Heyflow and Planeco Building, we stopped asking “What keywords should we target?” and started asking “Where are we not being cited, and why?” The results spoke for themselves: Planeco’s citation share went from 55% to over 110%, driven entirely by owned content improvements that monitoring data identified.
Here’s how the two approaches compare across key dimensions:
Dimension
Traditional keyword research
Monitoring-informed strategy
Primary input
Search volume, keyword difficulty
Citation gaps, source analysis, fan-out queries
Format decision
Based on SERP format
Based on which formats AI models actually cite
Language decision
Based on target market
Based on fan-out language data (43% English even for non-English prompts)
Depth decision
Based on competitor word count
Based on fan-out sub-query coverage
“Zero volume” signals
Ignored (no data available)
Often the highest-signal opportunities
Update trigger
Ranking drop
Citation share decline
How to set up monitoring for content strategy value
Before we get into the four monitoring-to-action loops, let’s be clear about what you’re monitoring and how to structure it. Most companies make the same mistake: they track too many prompts, focus on brand mentions, and never connect the data to content decisions.
Here’s the setup that actually produces strategic value:
Select 10 to 15 commercially meaningful prompts
Not awareness-stage, not informational. Decision-stage prompts that a buyer would actually type before making a purchase decision. Think “best [category] software for [use case],” “compare [your product] vs [competitor],” and “[category] for [specific industry/company size].”
Test prompt variations. A slight rephrasing can change which sources get cited entirely. Citation drift ranges from 40.5% (Perplexity) to 59.3% (Google AI Overviews), meaning the cited domains change frequently even for the same prompt. You need multiple variations of the same intent to get a reliable picture.
Map your competitor set
Include 3 to 5 direct competitors plus 2 to 3 adjacent competitors (companies in related categories that might get cited for your prompts). The adjacent competitors often reveal the most interesting content opportunities because they’re winning citations with content you haven’t considered creating.
Cover multiple AI platforms
At minimum: ChatGPT, Google AI Overviews, and Perplexity. If you target Enterprise, you might also consider adding Copilot. Each platform has different citation behaviors, and the discrepancies between them are where the strategic insights hide. If a competitor is cited heavily in ChatGPT but not in Google AI Overviews, that tells you something specific about the content type and format that’s winning.
Set a weekly review cadence
Not monthly. Not quarterly. The citation landscape shifts too fast. Only about 27% of fan-out sub-queries stay stable across repeated searches. A weekly 30-minute review of your monitoring dashboard, focused on changes in citation patterns rather than absolute numbers, is the minimum cadence that produces actionable insights.
The 4 monitoring-to-action loops
This is the operational framework we use at Radyant to turn monitoring data into content decisions. Each loop takes a specific type of monitoring output and converts it into a specific type of content action.
Loop 1: Citation gap analysis to content creation priorities
This is the most direct monitoring-to-action loop. You look at which domains and pages get cited for your commercially meaningful prompts, identify where competitors appear and you don’t, and prioritize content creation to close those gaps.
What to look for in monitoring data
The key insight most teams miss: monitoring competitor citations is more valuable than monitoring your own brand mentions. The most actionable data isn’t “we were mentioned in 40% of prompts.” It’s “G2 review pages, a competitor’s help center article, and a specific YouTube video keep getting cited for prompts we should own.”
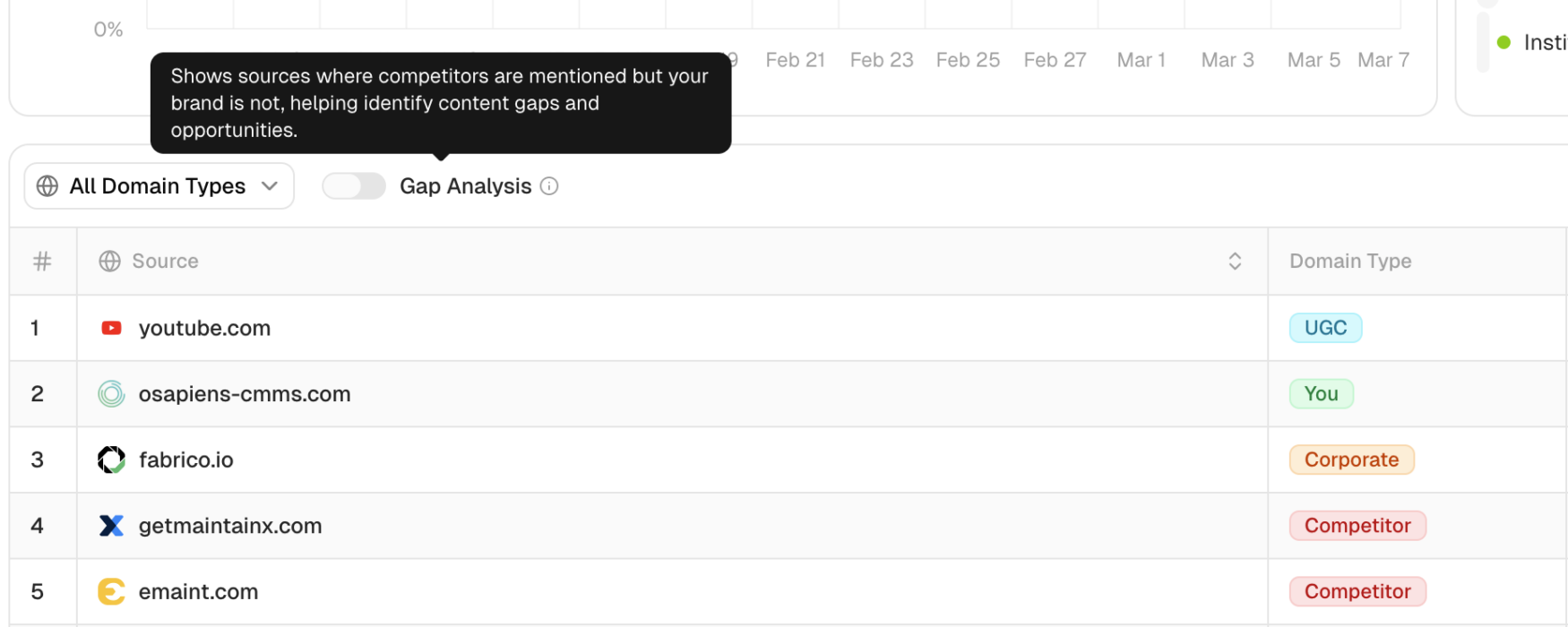
Citation gap analysis in Peec AI
When you run citation gap analysis, you’re looking for three patterns:
-
Topics where competitors are cited and you have no content at all. This is the clearest signal. Create the content.
-
Topics where you have content but it’s not being cited. This means your content exists but isn’t the best answer. Improve it.
-
Topics where third-party sources (G2, Capterra, Reddit) are cited instead of any vendor’s owned content. This signals an opportunity to create owned content that’s better than the third-party source.
How to prioritize gaps
Not all citation gaps are equal. Prioritize based on commercial intent. A gap on “best [category] software for enterprise” matters more than a gap on “what is [category].” Map each gap to a stage in the buyer journey and work backward from the decision stage.
The AI Overviews citation data shows an important nuance here: only 38% of AI Overviews cited pages also appeared in the top 10 organic results. The remaining citations split between positions 11 to 100 (31.2%) and beyond position 100 (31.0%). This means traditional ranking position is a poor predictor of citation success. A page that ranks #47 in Google can still be the primary citation source in AI Overviews if it’s the best answer to the specific sub-query.
Real example: “Zero volume” topics that drive pipeline
When we built the programmatic content strategy for Planeco Building, monitoring and audience research identified dozens of topics that Semrush showed as having zero search volume. Traditional keyword research would have dismissed every single one. We created 247 pages targeting these topics in 7 days. The result: 2,190 net new clicks in 3 months and 60+ leads in under 6 months.
Citation gap analysis works on the same principle. When monitoring shows a competitor being cited for a topic you don’t cover, that’s a signal regardless of what keyword tools say about volume.
Loop 2: Format opportunity analysis to format decisions
This loop answers a question that keyword research can’t: Should you create a blog post, a YouTube video, a help center article, or something else?
Monitoring data reveals which content formats AI models prefer to cite for different query types. And the results are often surprising.
The Heyflow YouTube discovery
When we started monitoring AI Search citations for Heyflow, the data showed something interesting: YouTube was the second most cited domain in their prompt set.
This insight came directly from monitoring data. No keyword research tool would have surfaced it. Based on this finding, we made YouTube optimization a priority, pushing 20+ video optimizations live. The videos started appearing prominently embedded in AI Overviews.
The broader data supports this pattern. As we documented in our YouTube AI Search citation framework:
-
YouTube appears in 16% of LLM answers (vs. 10% for Reddit)
-
YouTube accounts for 29.5% of Google AI Overviews citations
-
40.83% of AI-cited YouTube videos had fewer than 1,000 views (popularity doesn’t predict citations)
-
Long-form video accounts for 94% of AI citations; Shorts contribute just 5.7%
Help center content as a hidden citation source
Another format insight that monitoring consistently reveals in B2B SaaS: help center and documentation pages get cited for feature-specific queries that marketing pages miss entirely. When a buyer asks ChatGPT “Does [product] integrate with Salesforce?”, the AI model often cites a help center article rather than a marketing page because the help center provides the specific, factual answer.
If your monitoring data shows competitor help center pages getting cited for prompts you care about, that’s a signal to invest in your own help center content, not just your blog.
Format decision framework
Monitoring signal
Format action
YouTube videos cited for your prompts
Create/optimize long-form YouTube content (not Shorts)
Competitor help center pages cited
Build out help center content for feature-specific queries
Blog posts cited but with high citation drift
Create more comprehensive, frequently updated blog content
Third-party review sites (G2, Capterra) cited
Improve owned comparison/review content to compete
No consistent format pattern
Default to depth-first blog content with structured data
Loop 3: Multi-language citation analysis to translation decisions
This loop is especially relevant for companies operating in non-English markets (DACH, EU, LATAM, APAC), and it produces one of the most non-obvious content strategy insights we’ve found.
The fan-out language phenomenon
When someone types a prompt in German, French, or Spanish into ChatGPT, the model doesn’t just search in that language. Peec AI’s analysis of 10M+ ChatGPT prompts found that 43% of background searches ran in English, even for non-English prompts. The filtered data showed that 78% of non-English prompt runs included at least one English-language fan-out query.
The implications for content strategy are significant: if you only have content in your local language, you’re invisible to nearly half the background searches that ChatGPT runs when your potential customers ask questions in their native language.
No language was immune. Turkish-language prompts included English fan-outs most often at 94%. Spanish-language prompts were lowest at 66%. No non-English language in the dataset fell below 60%.
The deeploi dual-language citation
We saw this play out directly with a client. For deeploi, both the German original AND the English translation of the same content were cited separately in AI Overviews for “best IT onboarding software.” Same content, two citation spots. One piece of content, translated into English, doubled their citation surface for that prompt.
This isn’t a theoretical insight. It’s a repeatable content strategy: translate your most commercially important content into English to capture the hidden English queries that AI models run in the background.
We’ve written a detailed guide on the English translation strategy for fan-out queries that covers the full methodology, including which content to prioritize for translation and how to structure the English versions for maximum citation potential.
What monitoring data tells you about language priorities
Look at your citation gap analysis across platforms. If you see English-language competitor content being cited for prompts that your audience types in German (or any other language), that’s a direct signal to create English versions of your key content. The monitoring data makes this visible in a way that traditional analytics never could.
Loop 4: Fan-out query analysis to content depth decisions
This is the most technically nuanced loop, and it answers the question: How deep does your content need to go to get cited?
How fan-out queries work
When you type a prompt into ChatGPT, Google AI Mode, or Perplexity, the model doesn’t run a single search. It decomposes your prompt into multiple parallel sub-queries, retrieves content for each, and synthesizes the results. Research from Seer Interactive found that Gemini 3 generates an average of 10.7 fan-out queries per prompt, with a maximum of 28 from a single prompt. That’s up 78% from the average of 6.01 in Gemini 2.5.
Each of those sub-queries is a potential citation opportunity, and each one targets a specific sub-topic within the broader prompt. If your content covers the main topic but misses the sub-topics that fan-out queries target, you won’t get cited.
What this means for content depth
Seer Interactive’s research confirmed what we’ve observed in practice: “Gemini is consistently looking for comparisons, attributes, and deeper information when checking web sources. It’s not enough to cover surface-level information.”
Fan-out queries tend to target:
-
Comparisons (“X vs Y,” “alternatives to X”)
-
Specific attributes (“pricing,” “integrations,” “for enterprise”)
-
Use cases (“X for [specific industry],” “X for [specific workflow]”)
-
Reviews and validation (“X reviews,” “X pros and cons”)
If your monitoring data shows that you’re being cited for the main prompt but not for the sub-queries, that tells you exactly where to add depth. Create dedicated sections (or even dedicated pages) for the sub-topics that fan-out queries target.
Why continuous monitoring matters here
Fan-out queries are volatile. Only about 27% of fan-out sub-queries stay stable across repeated searches. The sub-queries that Gemini runs today for “best project management software” may be different next week. This is why a weekly monitoring cadence matters: you need to track which sub-topics the models are exploring over time, not just in a single snapshot.
The citation volatility data reinforces this: Google AI Overviews shows 59.3% citation drift, ChatGPT 54.1%, and Perplexity 40.5%. A single monitoring check tells you almost nothing. Trends over weeks and months tell you everything.
Turning monitoring signals into a content action plan
Here’s the decision matrix we use to translate monitoring signals into specific content actions:
Monitoring signal
Content action
Real example
Competitor cited for a topic you don’t cover
Create new owned content
Planeco: “0 volume” topics that generated 60+ leads
Competitor’s YouTube video cited, yours isn’t
Create or optimize video content
Heyflow: YouTube as 2nd most cited domain, 14.3% trial conversion
English content cited for non-English prompts
Translate key content to English
deeploi: same content cited in 2 languages separately
Fan-out queries cover sub-topics your content misses
Expand content depth with dedicated sections
Gemini 3 averaging 10.7 sub-queries per prompt
Your content is cited but citation share is declining
Update and expand existing content
Planeco: continuous monitoring caught share shifts early
Third-party sites cited instead of any vendor content
Create owned content that outperforms the third-party source
Help center content outperforming G2 for feature queries
The key principle behind every row in this table is the same: monitoring tells you what the current best answer is. Your job is to make your content the new best answer. This isn’t about gaming AI models. It’s about using data to identify where you can provide genuinely more useful content than what currently exists.
How to measure the impact of monitoring-informed content
Creating content based on monitoring data is only half the equation. You need to prove it works. And traditional attribution makes this difficult.
When someone asks ChatGPT for a recommendation, gets your brand mentioned, then types your brand name into Google, that shows up as “Direct” or “Organic” in your CRM. Never as “ChatGPT recommended us.” We’ve seen this repeatedly across clients: leads that self-report coming from AI Search show up as Direct traffic in analytics.
That’s why we use a four-signal attribution model:
-
Self-reported attribution. A “How did you hear about us?” field on forms, mandatory free-text so LLMs can analyze the responses at scale, plus a CRM field sales fills in after every call to catch what prospects say out loud.
-
AI-referral sessions. GA4 or server-log sessions that click straight through from ChatGPT, Perplexity, and similar. A verifiable floor of AI traffic, not the total.
-
Branded-search lift. Rising branded-query clicks in Search Console, the demand echo that follows a rise in citations.
-
AI Search visibility. Citation share across engines, the leading indicator the other three confirm.
None of these signals alone gives the full picture. You have to read them together. Our AI Search attribution guide covers the full setup.
What to do this week
You don’t need to implement all four loops simultaneously. Here’s how to start getting value from monitoring data in the next 7 days:
Step 1: Define 10 to 15 commercially meaningful prompts. Focus on decision-stage queries. What would a buyer type into ChatGPT right before evaluating solutions in your category? Write them down. Include 2 to 3 variations of each core intent.
Step 2: Run citation gap analysis against your top 3 competitors. Use whatever monitoring tool you have access to (Peec AI, Profound, Semrush’s AI Toolkit). If you don’t have a tool yet, you can do this manually by running your prompts across ChatGPT, Google AI Overviews, and Perplexity and documenting which domains get cited. It’s tedious but it works.
Step 3: Identify your single biggest citation gap and create a content brief to close it. Don’t try to fix everything at once. Find the one prompt where a competitor is consistently cited and you’re not, and create a content brief that makes your content the best answer for that specific prompt. Ship it within two weeks.
Then repeat. The monitoring-to-action loop is continuous, not a one-time exercise. As Malte Landwehr from Peec AI discussed on the Masters of Search podcast, the citation landscape shifts constantly. The companies that win are the ones with a system for responding to those shifts, not the ones with the best single piece of content.
FAQ
Which AI Search monitoring tools should I use?
The three most established options are Peec AI (strongest for citation tracking and fan-out query analysis), Profound (strong for competitive intelligence and multi-platform coverage), and Semrush’s AI Toolkit (best if you’re already in the Semrush ecosystem). All of them provide the data you need. None of them provide the strategy. We covered the key differences in our Peec AI vs. Profound breakdown.
How many prompts should I track?
Start with 10 to 15 commercially meaningful prompts. Quality of prompt selection matters more than volume. A focused set of decision-stage prompts with 2 to 3 variations each gives you more actionable data than 200 generic prompts. Expand gradually as you build pattern recognition for what types of prompts reveal the most useful citation gaps.
Does AI Search monitoring replace keyword research entirely?
For content strategy decisions, increasingly yes. Keyword research still has value for understanding search demand and identifying long-tail opportunities. But for deciding what content to create, in what format, and at what depth, monitoring data is a more reliable input. The two approaches are complementary, but monitoring should be the primary driver of your content calendar.
How do I prove the ROI of monitoring-informed content to my leadership team?
Track three things: citation share over time (are you being cited more?), self-reported attribution (are leads saying they found you through AI Search?), and pipeline from monitoring-identified content (did the content you created based on citation gaps generate leads?). Our four-signal attribution model gives you the full measurement framework. For Planeco Building, we could directly connect citation share growth to a 5x increase in organic leads.
Should I create English content even if my market is German (or another non-English language)?
Yes, for your most commercially important content. The data is clear: 78% of non-English ChatGPT prompt runs include at least one English-language fan-out query. If you only have German content, you’re invisible to those background searches. Translate your top 10 to 15 commercial pages into English. Our English translation guide for fan-out queries covers the full methodology.
How often should I review monitoring data for content strategy purposes?
Weekly, for 30 minutes minimum. Focus on changes in citation patterns rather than absolute numbers. Monthly, do a deeper review where you update your content priorities based on accumulated data. Quarterly reviews are too infrequent given citation volatility rates of 40 to 59% across platforms. The companies getting the most value from monitoring treat it as an always-on intelligence layer, not a periodic reporting exercise.